I digital innovasjon er data ofte den eneste og viktigste råvaren. Det er data som forer Teslas kjøreopplevelse og utvikling, Amazon’s Alexa stemmeassistent, og Google’s søkemotor. Det er tilgang på data om oss forbrukere som gir Facebook en forretningsmodell, som dreier GE fra et industriselskap til et prediksjonsselskap og som gjør Norgesgruppen i stand til å rette annonser mot oss for produkter vi ikke trodde vi trengte.
Prediksjon er sentral for alle disse nye forretningsmodellene. Store mengder ustrukturerte data gjør oss i stand til å finne mønstre som kan brukes til å predikere fremtidig adferd. Et eksempel er hvordan GE brukte sine data om sine industrielle produkter til å forbedre kundenes opplevelser og maskinenes ytelse. Et annet er Telenor som med å analysere brukerdata kunne predikere spredningen av dengufeber i Pakistan. Et tredje er hvordan data blir brukt til å lage bedre mobile løsninger for mennesker med mentale problemer. Trenden vi observerer er rimelig klar – selskapers fokus går fra produkt til plattform.
Med andre ord er det ikke bilen Tesla selger. Det er kjøreopplevelsen. Det er ikke et konkret søkeverktøy Google selger. Det er prediksjon om hva vi egentlig er ute etter basert på noen få ord vi plasserer i søkefeltet. Og det er ikke mikrobølgeovnen til Amazon vi kjøper. Nei, vi kjøper et system som gjør hverdagen enklere for oss.
I en slik overgang fra produkt til plattform er verdien av plattformen veldig viktig. Og den er en funksjon av datamengden. Men på en annen måte enn vi først kanskje tenker oss.
For data har alltid vært viktig i prediksjon. Alle som har jobbet med regresjonsanalyser eller andre statistiske teknikker vet at vi kan stole mer på resultatene dersom vi har større datamengde sammenliknet med tilfeller der vi har få observasjoner.
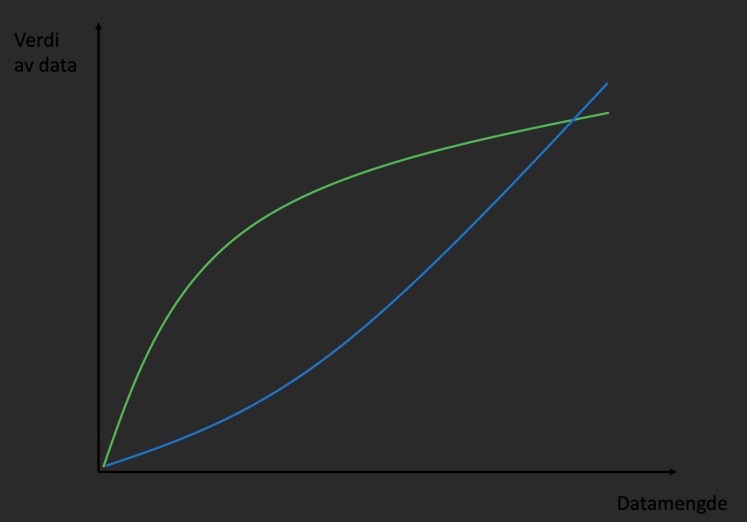
I klassisk prediksjon bidrar de 10 første observasjonene til en vesentlig forbedring i prediksjon. Men dersom vi legger på 10 observasjoner på toppen av 100 000 eksisterende observasjoner, vil effekten av de 10 siste være liten sammenliknet med de 10 første. Vi sier ofte at data har avtagende grensenytte. Altså er det lite å hente på å skaffe 40 000 nye observasjoner dersom vi har 400 000 fra før. Dette fenomenet med avtagende grensenytte er typisk for alle typer råvarer og input i produksjon. I figuren under er dette forholdet tegnet inn med en grønn linje.
Men i en plattformlogikk er det andre forhold som kommer inn. For mens Google sin søkemotor kanskje ikke blir så mye bedre av 10 000 ekstra observasjoner på toppen av de milliarder de allerede har, men de kan levere et relativt my bedre produkt sammenliknet med f.eks Bing. Og for oss som søker og opplever at Google oftere «tipper» rett på våre søk og gir oss treff med høyere relevans, så vil vi foretrekke Google for alle våre søk. Og når vi har kommet inn i Google’s økosystem (deres plattform), så er det ofte mye styr å bytte over til en annen plattform. Med andre ord er det stor verdi for Google i å kunne være marginalt bedre enn Bing. På denne måten vil ikke den samme loven om avtagende grensenytte gjelde når produkt går til plattform. I stedet ser det ut til at det er økende grensenytte (tegnet inn som blå linje i figuren under). Dette betyr det vil være økende etterspørsel etter gode data utover i plattformens livssyklus.

Så hvilke strategiske implikasjoner kan vi dra av dette. Jeg vil trekke frem to ting:
-
Dersom du er et selskap som ser kundedata som en viktig innsatsfaktor i din egen reise fra produkt til plattform så bør tilgang til data sikres gjennom allianser eller kjøp av data fra tredjepart. Langsiktig konkurransefortrinn vil avgjøres av din evne til å sikre tilgang til data på lang sikt.
-
Måten ditt selskap ser strategi på vil være avgjørende. Fokus på «hva som kreves av deg for å levere innovasjon og slå konkurrentene» vil ikke være tilstrekkelig. I tillegg må beslutningstaker stille seg følgende to spørsmål:
-
Hvem flere trenger å skape innovasjon for at min innovasjon betyr noe? – Dette er co-innovasjonsperspektivet hvor effekten av min innovasjon er en funksjon av andres. Eksempler her er at Amazon vil ikke kunne selge en god smarthjem løsning dersom nødvendige komponenter (lyspærer og stikkontakter) ikke eksisterer.
-
Hvilke andre må adoptere min innovasjon for at sluttkunden skal kunne oppleve et fullstendig verdiforslag? – Her er det snakk om å styrke adopsjonskjeden. Med dette mener vi tjenester og produkter bygd rundt din egen innovasjon. Et klassisk eksempel er at Apple iPhone ville vært vesentlig mindre verdt for kunden uten et rikt og åpent økosystem av apper og tilhørende tjenester.
I møte med økende grensenytte av data for å bedre din plattform, er fokus på gode allianser og tilgang på rike datakilder et vesentlig poeng. I tillegg bør beslutningstakere adoptere en større linse i sitt strategiarbeid. Uansett er vi tidlig i prosessen med å forstå data som råvare i digital innovasjon.





 I
I Haskell og Westlake trekker frem flere konsekvenser av fremveksten av IA. Og en full gjennomgang av disse er i overkant langt for en blogpost. Men blant trekkene som de relativt overbevisende viser til er:
Haskell og Westlake trekker frem flere konsekvenser av fremveksten av IA. Og en full gjennomgang av disse er i overkant langt for en blogpost. Men blant trekkene som de relativt overbevisende viser til er: